
You have to see it for yourself.
Matrices are of fundamental importance in 3D math, where they are primarily used to describe the relationship between two coordinate spaces. They do this by defining a computation to transform vectors from one coordinate space to another.
This chapter introduces the theory and application of matrices. Our discussion will follow the pattern set in Chapter 2 when we introduced vectors: mathematical definitions followed by geometric interpretations.
- Section 4.1 discusses some of the basic properties and operations of matrices strictly from a mathematical perspective. (More matrix operations are discussed in Chapter 6.)
- Section 4.2 explains how to interpret these properties and operations geometrically.
- Section 4.3 puts the use of matrices in this book in context within the larger field of linear algebra.
4.1Mathematical Definition of Matrix
In linear algebra, a matrix is a rectangular grid of numbers arranged into rows and columns. Recalling our earlier definition of vector as a one-dimensional array of numbers, a matrix may likewise be defined as a two-dimensional array of numbers. (The “two” in “two-dimensional array” comes from the fact that there are rows and columns, and should not be confused with 2D vectors or matrices.) So a vector is an array of scalars, and a matrix is an array of vectors.
This section presents matrices from a purely mathematical perspective. It is divided into eight subsections.
- Section 4.1.1 introduces the concept of matrix dimension and describes some matrix notation.
- Section 4.1.2 describes square matrices.
- Section 4.1.3 interprets vectors as matrices.
- Section 4.1.4 describes matrix transposition.
- Section 4.1.5 explains how to multiply a matrix by a scalar.
- Section 4.1.6 explains how to multiply a matrix by another matrix.
- Section 4.1.7 explains how to multiply a vector by a matrix.
- Section 4.1.8 compares and contrasts matrices for row and column vectors.
4.1.1Matrix Dimensions and Notation
Just as we defined the dimension of a vector by counting how many numbers it contained, we will
define the size of a matrix by counting how many rows and columns it contains. We say that a
matrix with
This
As we mentioned in Section 2.1, in this book we represent a matrix
variable with uppercase letters in boldface, for example,
The notation
4.1.2Square Matrices
Matrices with the same number of rows and columns are called square matrices and are of
particular importance. In this book, we are interested in
The diagonal elements of a square matrix are those elements for which the row and column
indices are the same. For example, the diagonal elements of the
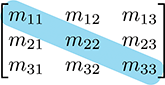
If all nondiagonal elements in a matrix are zero, then the matrix is a diagonal matrix. The
following
A special diagonal matrix is the identity matrix. The identity matrix of dimension
Often, the context will make clear the dimension of the identity matrix used in a particular
situation. In these cases we omit the subscript and refer to the identity matrix simply as
The identity matrix is special because it is the multiplicative identity element for matrices. (We discuss matrix multiplication in Section 4.1.6.) The basic idea is that if you multiply a matrix by the identity matrix, you get the original matrix. In this respect, the identity matrix is for matrices what the number 1 is for scalars.
4.1.3Vectors as Matrices
Matrices may have any positive number of rows and columns, including one. We have already
encountered matrices with one row or one column: vectors! A vector of dimension
Until now, we have used row and column notations interchangeably. Indeed, geometrically they are identical, and in many cases the distinction is not important. However, for reasons that will soon become apparent, when we use vectors with matrices, we must be very clear if our vector is a row or column vector.
4.1.4Matrix Transposition
Given an
For vectors, transposition turns row vectors into column vectors and vice versa:
Transposing converts between row and column vectorsTransposition notation is often used to write column vectors inline in a paragraph, such as
Let's make two fairly obvious, but significant, observations regarding matrix transposition.
-
-
Any diagonal matrix
4.1.5Multiplying a Matrix with a Scalar
A matrix
4.1.6Multiplying Two Matrices
In certain situations, we can take the product of two matrices. The rules that govern when matrix multiplication is allowed and how the result is computed may at first seem bizarre.
An
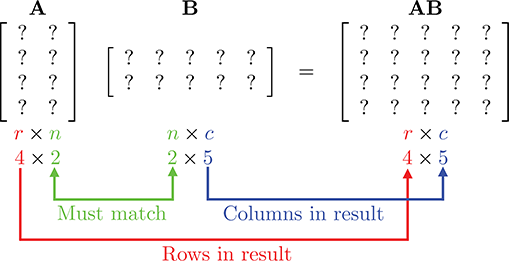
If the number of columns in
Matrix multiplication is computed as follows: let the matrix
This looks complicated, but there is a simple pattern. For each element
Let's look at an example of how to compute
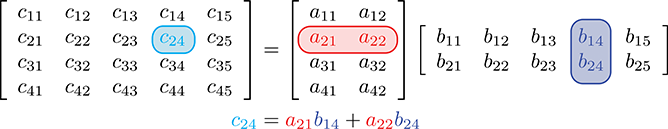
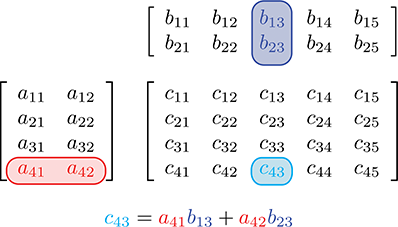
Another way to help remember the pattern for matrix multiplication is to write
For geometric applications, we are particularly interested in multiplying square matrices—the
Let's look at a
Applying the general matrix multiplication formula to the
Here is a
Beginning in Section 6.4 we also use
A few notes concerning matrix multiplication are of interest:
-
Multiplying any matrix
-
Matrix multiplication is not commutative. In general,
-
Matrix multiplication is associative:
(Of course, this assumes that the sizes of
-
Matrix multiplication also associates with multiplication by a scalar or a vector:
-
Transposing the product of two matrices is the
same as taking the product of their transposes in reverse order:
This can be extended to more than two matrices:
4.1.7Multiplying a Vector and a Matrix
Since a vector can be considered a matrix with one row or one column, we can multiply a vector
and a matrix by applying the rules discussed in the previous section. Now it becomes very
important whether we are using row or column vectors.
Equations (4.4)–(4.7)
show how 3D row and column vectors may be pre- or post-multiplied by a
As you can see, when we multiply a row vector on the left by a matrix on the right, as in Equation (4.4), the result is a row vector. When we multiply a matrix on the left by a column vector on the right, as in Equation (4.5), the result is a column vector. (Please observe that this result is a column vector, even though it looks like a matrix.) The other two combinations are not allowed: you cannot multiply a matrix on the left by a row vector on the right, nor can you multiply a column vector on the left by a matrix on the right.
Let's make a few interesting observations regarding vector-times-matrix multiplication. First, each element in the resulting vector is the dot product of the original vector with a single row or column from the matrix.
Second, each element in the matrix determines how much “weight” a particular element in the input
vector contributes to an element in the output vector. For example, in
Equation (4.4) when row vectors are used,
Third, vector-times-matrix multiplication distributes over vector addition, that is, for vectors
Finally, and perhaps most important of all, the result of the multiplication is a linear combination of the rows or columns of the matrix. For example, in Equation (4.5), when column vectors are used, the resulting column vector can be interpreted as a linear combination of the columns of the matrix, where the coefficients come from the vector operand. This is a key fact, not just for our purposes but also for linear algebra in general, so bear it in mind. We will return to it shortly.
4.1.8Row versus Column Vectors
This section explains why the distinction between row and column vectors is significant and gives our rationale for preferring row vectors. In Equation (4.4), when we multiply a row vector on the left with matrix on the right, we get the row vector
Compare that with the result from Equation (4.5), when a column vector on the right is multiplied by a matrix on the left:
Disregarding the fact that one is a row vector and the other is a column vector, the values for the components of the vector are not the same! Thisis why the distinction between row and column vectors is soimportant.
Although some matrices in video game programming do represent arbitrary systems of equations, a
much larger majority are transformation matrices of the type we have been describing, which express
relationships between coordinate spaces. For this purpose, we find row vectors to be preferable
for the “eminently sensible” reason [1] that the order of transformations
reads like a sentence from left to right. This is especially important when more than one
transformation takes place. For example, if we wish to transform a vector
Unfortunately, row vectors lead to very “wide” equations; using column vectors on the right certainly makes things look better, especially as the dimension increases. (Compare the ungainliness of Equation (4.4) with the sleekness of Equation (4.5).) Perhaps this is why column vectors are the near universal standard in practically every other discipline. For most video game programming, however, readable computer code is more important than readable equations. For this reason, in this book we use row vectors in almost all cases where the distinction is relevant. Our limited use of column vectors is for aesthetic purposes, when either there are no matrices involved or those matrices are not transformation matrices and the left-to-right reading order is not helpful.
As expected, different authors use different conventions. Many graphics books and application programming interfaces (APIs), such as DirectX, use row vectors. But other APIs, such as OpenGL and the customized ports of OpenGL onto various consoles, use column vectors. And, as we have said, nearly every other science that uses linear algebra prefers column vectors. So be very careful when using someone else's equation or source code that you know whether it assumes row or column vectors.
If a book uses column vectors, its equations for matrices will be transposed compared to the
equations we present in this book. Also, when column vectors are used, vectors are pre-multiplied
by a matrix, as opposed to the convention chosen in this book, to multiply row vectors by a matrix
on the right. This causes the order of multiplication to be reversed between the two styles when
multiple matrices and vectors are multiplied together. For example, the multiplication
Mistakes like this involving transposition can be a common source of frustration when programming 3D math. Luckily, with properly designed C++ classes, direct access to the individual matrix elements is seldom needed, and these types of errors can be minimized.
4.2Geometric Interpretation of Matrix
In general, a square matrix can describe any linear transformation. In Section 5.7.1, we provide a complete definition of linear transformation, but for now, it suffices to say that a linear transformation preserves straight and parallel lines, and that there is no translation—that is, the origin does not move. However, other properties of the geometry, however, such as lengths, angles, areas, and volumes, are possibly altered by the transformation. In a nontechnical sense, a linear transformation may “stretch” the coordinate space, but it doesn't “curve” or “warp” it. This is a very useful set of transformations, including
- rotation
- scale
- orthographic projection
- reflection
- shearing
Chapter 5 derives matrices that perform all of these operations. For now, though, let's just attempt a general understanding of the relationship between a matrix and the transformation it represents.
The quotation at the beginning of this chapter is not only a line from a great movie, it's true for
linear algebra matrices as well. Until you develop an ability to visualize a matrix, it will just
be nine numbers in a box. We have stated that a matrix represents a coordinate space
transformation. So when we visualize the matrix, we are visualizing the transformation, the new
coordinate system. But what does this transformation look like? What is the relationship between a
particular 3D transformation (i.e. rotation, shearing, etc.) and those nine numbers inside a
To begin to answer this question, let's watch what happens when the standard basis vectors
In other words, the first row of
Once we know what happens to those basis vectors, we know everything about the transformation! This is because any vector can be written as a linear combination of the standard basis, as
Multiplying this expression by our matrix on the right, we have
Here we have confirmed an observation made in Section 4.1.7: the result of a
vector
Let's summarize what we have said.
We now have a simple way to take an arbitrary matrix and visualize what sort of transformation
the matrix represents. Let's look at a couple of examples—first, a 2D example to get ourselves
warmed up, and then a full-fledged 3D example. Examine the following
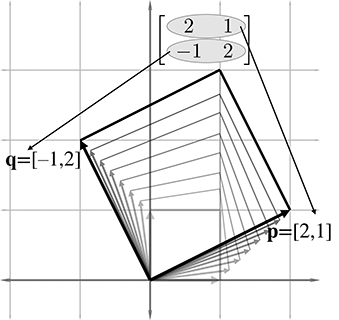
What sort of transformation does this matrix represent? First, let's extract the basis vectors
Figure 4.1 shows these vectors in the Cartesian plane, along with the “original”
basis vectors (the

As Figure 4.1 illustrates, the
Of course, all vectors are affected by a linear transformation, not just the basis vectors. We can get a very good idea what this transformation looks like from the L, and we can gain further insight on the effect the transformation has on the rest of the vectors by completing the 2D parallelogram formed by the basis vectors, as shown in Figure 4.2.
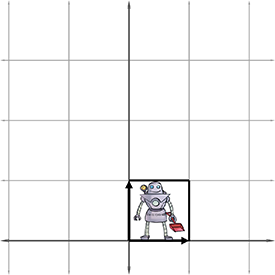
This parallelogram is also known as a “skew box.” Drawing an object inside the box can also help, as illustrated in Figure 4.3.
|
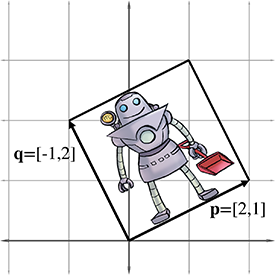
|
Now it is clear that our example matrix
We can extend the techniques we used to visualize 2D transformations into 3D. In 2D, we had two basis vectors that formed an L—in 3D, we have three basis vectors, and they form a “tripod.” First, let's show an object before transformation. Figure 4.4 shows a teapot, a unit cube, and the basis vectors in the “identity” position.
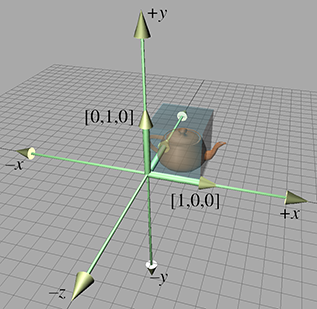
(To avoid cluttering up the diagram, we have not labeled the
Now consider the 3D transformation matrix
Extracting the basis vectors from the rows of the matrix, we can visualize the transformation represented by this matrix. The transformed basis vectors, cube, and teapot are shown in Figure 4.5.
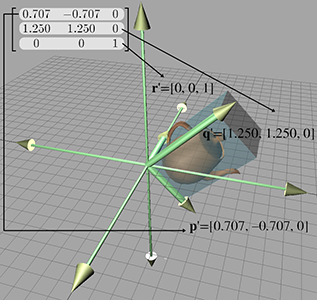
As we can see, the transformation consists of a clockwise rotation of
By interpreting the rows of a matrix as basis vectors, we have a tool for deconstructing a matrix. But we also have a tool for constructing one! Given a desired transformation (i.e., rotation, scale, and so on), we can derive a matrix that represents that transformation. All we have to do is figure out what the transformation does to the basis vectors, and then place those transformed basis vectors into the rows of a matrix. We use this tool repeatedly in Chapter 5 to derive the matrices to perform basic linear transformations such as rotation, scale, shear, and reflection.
The bottom line about transformation matrices is this: there's nothing especially magical about matrices. Once we understand that coordinates are best understood as coefficients in a linear combination of the basis vectors (see Section 3.3.3), we really know all the math we need to know to do transformations. So from one perspective, matrices are just a compact way to write things down. A slightly less obvious but much more compelling reason to cast transformations in matrix notation is to take advantage of the large general-purpose toolset from linear algebra. For example, we can take simple transformations and derive more complicated transformations through matrix concatenation; more on this in Section 5.6.
Before we move on, let's review the key concepts of Section 4.2.
- The rows of a square matrix can be interpreted as the basis vectors of a coordinate space.
- To transform a vector from the original coordinate space to the new coordinate space, we multiply the vector by the matrix.
- The transformation from the original coordinate space to the coordinate space defined by these basis vectors is a linear transformation. A linear transformation preserves straight lines, and parallel lines remain parallel. However, angles, lengths, areas, and volumes may be altered after transformation.
- Multiplying the zero vector by any square matrix results in the zero vector. Therefore, the linear transformation represented by a square matrix has the same origin as the original coordinate space—the transformation does not contain translation.
- We can visualize a matrix by visualizing the basis vectors of the coordinate space after transformation. These basis vectors form an `L' in 2D, and a tripod in 3D. Using a box or auxiliary object also helps in visualization.
4.3The Bigger Picture of Linear Algebra
At the start of Chapter 2, we warned you that in this book we are focusing on just one small corner of the field of linear algebra—the geometric applications of vectors and matrices. Now that we've introduced the nuts and bolts, we'd like to say something about the bigger picture and how our part relates to it.
Linear algebra was invented to manipulate and solve systems of linear equations. For example, a typical introductory problem in a traditional course on linear algebra is to solve a system of equations such as
which has the solution
Matrix notation was invented to avoid the tedium involved in duplicating every
Perhaps the most direct and obvious place in a video game where a large system of equations must be solved is in the physics engine. The constraints to enforce nonpenetration and satisfy user-requested joints become a system of equations relating the velocities of the dynamic bodies. This large system3 is then solved each and every simulation frame. Another common place for traditional linear algebra methods to appear is in least squares approximation and other data-fitting applications.
Systems of equations can appear where you don't expect them. Indeed, linear algebra has exploded in importance with the vast increase in computing power in the last half century because many difficult problems that were previously neither discrete nor linear are being approximated through methods that are both, such as the finite element method. The challenge begins with knowing how to transform the original problem into a matrix problem in the first place, but the resulting systems are often very large and can be difficult to solve quickly and accurately. Numeric stability becomes a factor in the choice of algorithms. The matrices that arise in practice are not boxes full of random numbers; rather, they express organized relationships and have a great deal of structure. Exploiting this structure artfully is the key to achieving speed and accuracy. The diversity of the types of structure that appear in applications explains why there is so very much to know about linear algebra, especially numerical linear algebra.
This book is intended to fill a gap by providing the geometric intuition that is the bread and butter of video game programming but is left out of most linear algebra textbooks. However, we certainly know there is a larger world out there for you. Although traditional linear algebra and systems of equations do not play a prominent role for basic video game programming, they are essential for many advanced areas. Consider some of the technologies that are generating buzz today: fluid, cloth, and hair simulations (and rendering); more robust procedural animation of characters; real-time global illumination; machine vision; gesture recognition; and many more. What these seemingly diverse technologies all have in common is that they involve difficult linear algebra problems.
One excellent resource for learning the bigger picture of linear algebra and scientific computing is Professor Gilbert Strang's series of lectures, which can be downloaded free from MIT OpenCourseWare at ocw.mit.edu. He offers a basic undergraduate linear algebra course as well as graduate courses on computational science and engineering. The companion textbooks he writes for his classes [3][2] are enjoyable books aimed at engineers (rather than math sticklers) and are recommended, but be warned that his writing style is a sort of shorthand that you might have trouble understanding without the lectures.
Exercises
- For each matrix, give the dimensions of the matrix and identify whether it is square and/or diagonal.
- Transpose each matrix.
- Find all the possible pairs of matrices that can be legally multiplied, and give the dimensions of the resulting product. Include “pairs” in which a matrix is multiplied by itself. (Hint: there are 14 pairs.)
-
Compute the following matrix products. If the product is not possible,
just say so.
-
(a)
-
(b)
-
(c)
-
(d)
-
(e)
-
(f)
-
(g)
-
(h)
-
(a)
-
For each of the following matrices, multiply on the left by the row vector
-
(a)
-
(b)
-
(c)
This is an example of a symmetric matrix. A square matrix is symmetric if -
(d)
This is an example of a skew symmetric or antisymmetric matrix. A square matrix is skew symmetric if
-
(a)
-
Manipulate the following matrix expressions to remove the parentheses.
-
(a)
-
(b)
-
(c)
-
(d)
-
(a)
-
Describe the transformation
-
(a)
-
(b)
-
(c)
-
(d)
-
(e)
-
(f)
-
(a)
-
For 3D row vectors
-
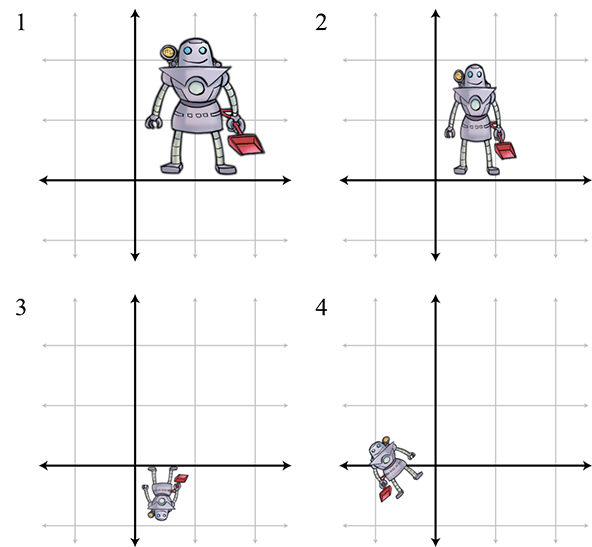
Match each of the following figures (1–4) with their corresponding transformations.
-
-
Given the
Matrices of this form arise when some continuous function is discretized. Multiplication by this first difference matrix is the discrete equivalent of continuous differentiation. (We'll learn about differentiation in Chapter 11 if you haven't already had calculus.) -
Given the
This matrix performs the discrete equivalent of integration, which as you might already know (but you certainly will know after reading Chapter 11) is the inverse operation of differentiation. -
Consider
-
Discuss your expectations of the product
-
Discuss your expectations of the product
-
Calculate both
-
Discuss your expectations of the product
and that means that one has got beyond being shocked,
although one preserves one's own moral aesthetic preferences.
- The problem of finding the parenthesization that minimizes the number of scalar multiplications is known as the matrix chain problem.
- It's rows in this book. If you're using column vectors, it's the columns of the matrix.
- It's a system of inequalities, but similar principles apply.